Explore Delta Lake:
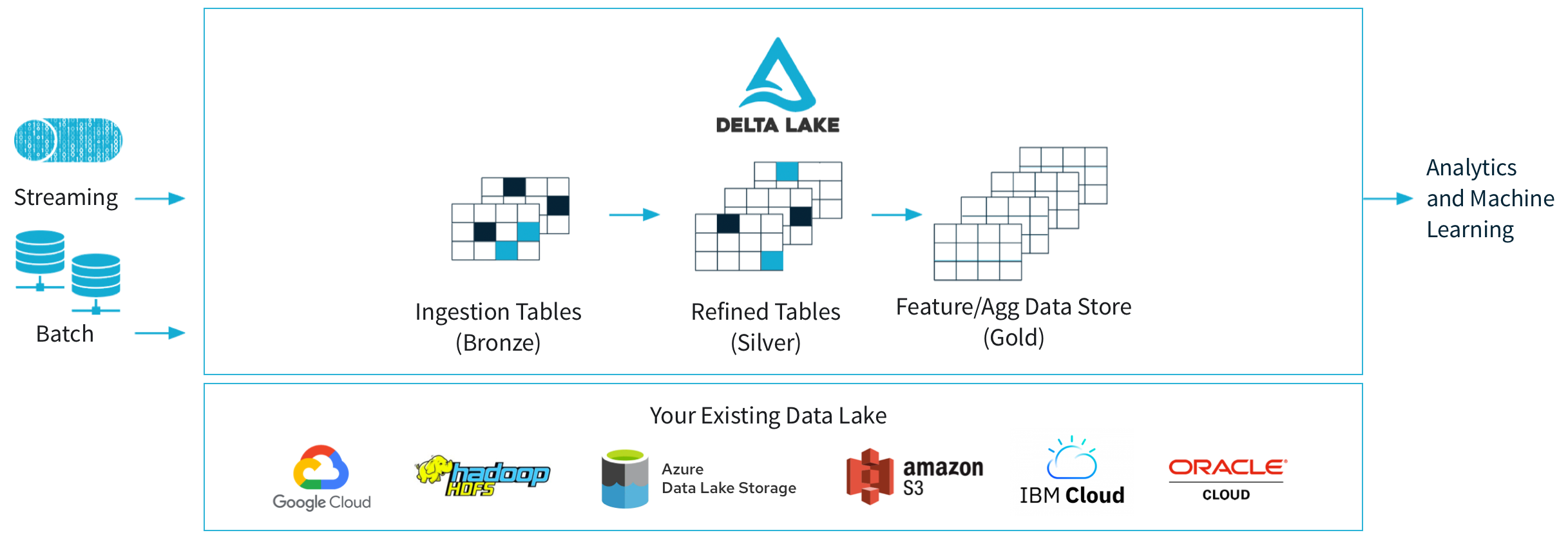
Delta Lake is an open-source data storage layer that runs on top of existing data lake systems, such as Apache Hadoop or Amazon S3. It was developed by Databricks, a company that provides a unified analytics platform for data engineering, data science, and machine learning.
Delta Lake provides ACID transactions, schema enforcement, and other data management features on top of data lakes, which are typically used for storing large volumes of unstructured and semi-structured data. By adding these features, Delta Lake makes data lakes more suitable for use cases where data quality, consistency, and reliability are important, such as data science, machine learning, and analytics.
Some of the key features of Delta Lake include:
ACID Transactions: Delta Lake provides transactional guarantees for both batch and streaming data. This means that data operations, such as inserts, updates, and deletes, are executed in an atomic, consistent, isolated, and durable (ACID) manner. ACID transactions ensure data integrity and consistency, even in the face of concurrent updates or failures.
Schema Enforcement: Delta Lake provides schema enforcement, which ensures that data adheres to a predefined schema. This feature allows for easier data validation, data quality checks, and data governance. Additionally, Delta Lake allows for schema evolution, meaning that the schema can be changed over time without disrupting existing data.
Ref.: https://delta.io/static/delta-hp-hero-bottom-46084c40468376aaecdedc066291e2d8.png
Time Travel: Delta Lake provides time travel, which allows for versioning and historical querying of data. This feature enables data analysts and data scientists to query data at different points in time, enabling them to track changes and understand trends over time.
Unified Batch and Streaming: Delta Lake supports both batch and streaming workloads, allowing for real-time data processing and analytics. This feature makes it easier to build end-to-end data pipelines that can handle both batch and streaming data, without requiring separate data storage or processing systems.
Open Source: Delta Lake is an open-source project, meaning that it is freely available to use and contribute to. This allows organizations to customize and extend Delta Lake to meet their specific needs and use cases.
Overall, Delta Lake provides a more reliable and consistent data storage layer on top of data lakes, making it easier for organizations to manage and analyze their data effectively. It has become a popular choice for data science and analytics workloads, particularly for organizations that use the Apache Spark processing engine.
Comments
Post a Comment